能够快速地错误定位,解决问题,是我们开发中非常重要的一种能力。
从浏览器控制台到运行Node.js的计算机终端,我们到处都会看到错误。
这篇文章重点介绍了在JS开发过程中可能遇到的 7 种错误类型。
1. RangeError 范围错误
当数字超出允许的值范围时,将抛出此错误;或者JS执行进入死循环。

我们有一个数组,带有两个元素的arr。 接下来,我们尝试将数组扩展为包含90 ** 99 = 2.9512665430652753e + 193元素。
这个数字超出了数组最大的长度范围。 运行它会抛出RangeError:

因为我们要增加arr数组的数量超出了JS指定的范围。
2. ReferenceError 引用错误
当对变量/项目的引用被破坏时,将引发此错误。 那是变量/项目不存在。

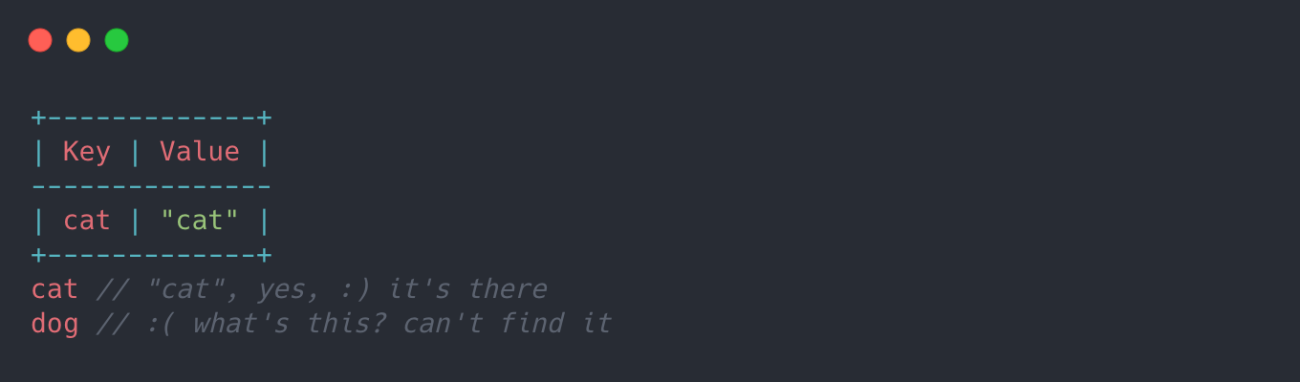
我们有一个变量cat初始化为"cat"。 接下来,我们参考cat变量和dog变量。 cat变量存在,而dog变量不存在。
cat将返回”cat”,而dog将引发参考错误,因为在环境记录中找不到名称dog。

每当我们创建或定义变量时,变量名称都会写入环境记录中。 此环境记录就像键值存储一样,

每当我们引用变量时,它都会存储程序中定义的变量。 当在记录中找到环境值并提取并返回值时,将以该变量的名称作为关键字搜索环境记录。 调用尚未定义的函数。
现在,当我们创建或定义一个没有赋值的变量时。 该变量以键作为变量名称写入环境记录,但该值将保持未定义状态。

稍后为变量分配值时,将在env记录中搜索该变量,当找到初始未定义值时,该赋值将被覆盖。

因此,当在环境记录中找不到变量名时,JS引擎会引发ReferenceError。
注意:未定义的变量不会抛出ReferenceError,因为它存在于环境记录中只是它的值尚未设置。
3. SyntaxError 语法错误
这是我们遇到的最常见的错误。 当我们键入JS引擎可以理解的代码时,会发生此错误。
解析期间,JS引擎捕获了此错误。 在JS引擎中,我们的代码经过不同的阶段,然后才能在终端上看到这些结果。
- tokenization 标记化
- parsing 解析
- interpreting 编译
标记化将代码的源分解为各个单元。 在此阶段,将对数字,关键字,文字,运算符进行整理并分别进行标记。
接下来,生成的令牌流将传递到解析阶段,由解析器处理。 这是从令牌流生成AST的地方。 AST是我们代码结构的抽象表示。
在这两个阶段,即标记化和解析,如果我们代码的语法/源不符合JS的语法规则,则会使阶段失败并引发SyntaxError。 例如,

单独的h代表什么? 那里的h破坏了代码。

因此,我们可以说语法错误发生在解析/编译期间。
4. TypeError 类型错误
当其他NativeError对象中没有一个是失败原因的适当指示时,TypeError用于指示操作失败。
对错误的数据类型执行操作时会发生TypeError。 可能是布尔值,但是找到了ing。
例如, 如果我们尝试将数字转换为大写,如下所示:

将抛出一个 TypeError

因为toUpperCase函数需要字符串数据类型。 toUpperCase函数是有意通用的; 它不需要其this值为String对象。 因此,可以将其转移到其他类型的对象中用作方法。
如果我们对Objects,Boolean,Symbol,null,undefined数据类型调用toUpperCase函数,则只有字符串会转换为大写或小写形式,我们将得到TypeError,因为它操作的数据类型错误。
5. URIError
这表明使用一种全局URI处理功能与其定义不兼容。
JS中的URI(统一资源指示符)具有以下功能:decodeURI,decodeURIComponent等。
如果我们使用错误的参数调用它们中的任何一个,我们将得到URIError

encodeURI,获取URI的未编码版本。 "%"不是正确的URI,因此引发了URIError。
如果对URI进行编码或解码有问题,则会引发URIError。
6. EvalError
在使用全局eval()函数时,此函数用于识别错误。
根据EcmaSpec 2018版: 此规范当前未使用此异常。 保留该对象是为了与本规范的先前版本兼容。
7. InternalError 内部错误
该错误在JS引擎内部发生,特别是当它有太多数据要处理并且堆栈增长超过其关键限制时。
当JS引擎被太多的递归,太多的切换情况等淹没时,就会发生这种情况
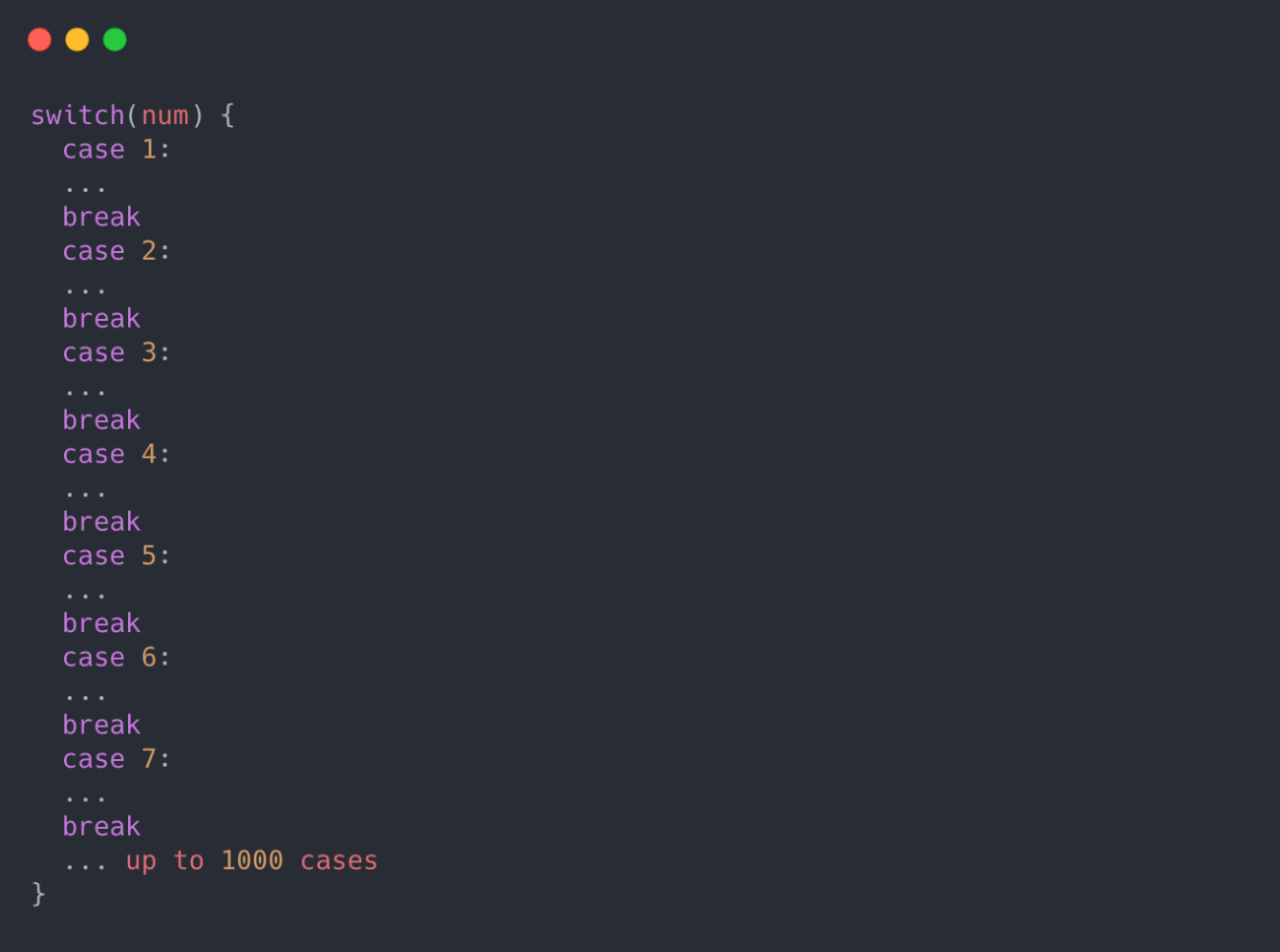
太多的递归,一个简单的例子是这样的:

总结
正如我们所说,没有人能避免犯错误。 就我们键入代码而言,这是一个稳定的事件。 为了克服它,我们需要知道可以抛出的本机错误的类型。 我们在这篇文章中列出了它们,并提供了一些示例来说明它们是如何遇到的。
因此,无论何时在终端或浏览器中引发错误,您现在都可以轻松发现错误发生的位置和方式,并编写更好,更不易出错的代码。
文/H5技术专家:阿宽老师
